현재 아톰의 코어 디자인은 초기 아톰을 거의 그대로 유지하고 있고,
인텔 또한 코어 자체는 변화 없이 이어질 것이라고 했고, 그렇게 했다.
성능 역시 그대로다. 이는 인텔이 아톰의 성능이 하향평준화 수준을 충족한다고 판단했기 때문이다.
아톰이 2세대로 넘어오면서 바뀐 것은, 멤컨 내장과 GPU내장, 네이티브 듀얼코어 정도이다.
그리고 머지않아 OakTrail이 출시됨으로써 2세대 아톰의 라인업은 마무리된다.
그 후 1년 반 정도 되면 3세대 아톰의 출시가 되어야 할 시점인 것이다.
이전에 올렸던 포스트에서 아톰과 밥캣을 다루면서 언급된
밥캣 다이디자인에 대한 추측글의 링크가 있었는데,
http://gigglehd.com/zbxe/4536851
필자는 이 가설에 대해 '맞다'라고 결론을 내렸었고, 여전히 맞다고 본다.
* 링크 원문에서 아래 추가된 내용에 대해서는 전혀 공감하지 않는다. -_-a
그보다 여기서 어떤 식으로든 밥캣은 공정차이가 있긴 해도 OoO이면서
아톰보다 적은 면적의 코어를 디자인해냈다.
이는 다이면적(=단가)이 적으면서 HT로 성능을 끌어냈다는 점에서
2세대에서도 기존 코어디자인을 유지했던 인텔에게 있어서
그 의의를 상실하게 만드는 점이 아닐 수 없다.
이런데도 인텔은 또 기존 본넬 아키텍쳐를 그냥 32nm로 우려먹을것인가?
이에 대해 본인은 순간 떠올린 아톰의 미래를 적어보고자 한다.
그 키워드중 하나는, 먼저 예전 본인이 언급했던 2코어 3스레드 SMT이다.
http://gigglehd.com/zbxe/3320432
아톰은 특이하게도 HT 효율이 +50%나 된다. 이런 특징에서 2코어 3스레드로 만들면,
사실상 HT off 상태의 아톰 3개코어를 쓰는 셈이 된다.
같은 경우의 듀얼코어 아톰에서 HT로 인해 코어마다 점유분산이 발생한다는 점에 비해
L1캐시 레벨에서 두 코어가 공유되는 2코어 3스레드는 우월할 수밖에 없다.
이건 이미 아톰이 처음 나왔던 시점에서 생각했던 것이고,
지금에와서는 역시 이것만으로는 부족하다.
그래서 생각한 다른 하나의 키워드. 그것은 바로 불도저의 CMT이다.
> 불도저와 밥캣의 구조는 이쪽을 참고 : http://gigglehd.com/zbxe/4437586
아톰이 단순한 코어 디자인을 충족시키는 IO 아키텍쳐임에도 불구하고
OoO를 쓴 밥캣에게 다이사이즈에서 밀린 이유가 무엇인가?
최근의 코어 디자인에서 상당한 공간을 차지하는 FPU 연산 중
SIMD 연산의 처리를 GPU의 SP에게 맡겼기 때문이 아닌가?
물론 인텔이 아톰 CPU에 SIMD 연산을 일임할 GPU를 넣는다고 하면,
GMA는 좀 그렇고.....라라비를 넣는다는 얘기가 되는데,
라라비를 넣는다고 치면, 사실 라라비의 코어 하나하나는 아톰과 유사한 면적이므로,
사실상 아톰 코어에 그런걸 GPU라고 탑재할 바에는 그냥 아톰 코어 수십개를 탑재하고
불도저처럼 가변적으로 특정 갯수의 코어를 GPU로 작동시키는게 나을 것 같다.
그러나 개발 기간과 기술 배경이 요구되므로 그건 더 미래의 일이고,
현재 3세대 아톰으로서는 그보다 빨리 완성할 수 있는 방법이 필요한 것이다.
여기서 인텔의 주특기인 '적재적소'가 쓰이게 될텐데, 그런 사례들을 짚어보자면,
인텔의 EM64T. 인텔은 네이티브 64비트인 IA64를 먼저 만들어 쓰고있었지만,
하위호환 64비트 IA. 즉 x86-64는 AMD가 먼저 만들어 썼다.
AMD의 64비트 프로세서가 상승세를 타자 인텔은 순식간에 만들어, 팔던 펜티엄4에 집어넣었다.
그뿐인가, 듀얼코어 역시 AMD가 듀얼코어 개발을 발표하자 인텔은
팔던 펜티엄4를 MCM을 이용해 AMD보다 먼저 듀얼코어를 내놓았고,
인텔이 네할렘에 와서 적용한 메모리 컨트롤러내장 CPU도
PC계열에선 AMD가 먼저 애슬론64에 적용했던 것이다.
그래서 CMT이다. 현재 아톰이 필요한 것은 성능.
캐시나 클럭 따위는 공정을 축소하면서 간단히 올릴 수 있는 것이고.
그 외에 성능을 올릴 수 있는 방법이 있다면 FPU 강화와 멀티코어일 것이다.
CPU 점유 분산으로 HT off시보다 최대 스레드 성능이 25%나 하락할 수 있는 문제는
2코어 3스레드 적용으로 해결된다. 그리고 하나로 묶인 2개 코어에서 그 이상의 탑재를 위해
다이 사이즈 절약은 필수요소이고, 아톰은 저단가 또한 목표하고 있으므로 또한 그렇다.
따라서 FPU 강화와 다이사이즈 절약을 동시에 충족하는 것이 CMT. CMT로 해결이 되는것이다.
또한 여기에 추가되는 사항은 32nm 공정이다.
그런데 이렇게 변화가 많아진 아키텍쳐에 새 공정을 적용하는 것은
인텔의 틱톡 전략에 반하는것이 아니냐라고 생각할 수 있지만, 그렇지 않다.
원래 초기부터 아톰은 처음 시도하는 아키텍쳐임에도 45nm공정의 스타트를 끊었고,
그런 시험적인 포시션의 제품군이여, 전략에 속해있었다.
이제와서 문제될 것은 없다. 이로써 아톰은 무식한 다이사이즈 축소로
밥캣으로 우쭐했던 AMD로부터 울트라 모바일 시장의 패권을 되찾는다......라는 시나리오다.
역시 공정도 줄고 코어. 특히 FPU 파이프라인을 손보는 만큼
AVX같은 물건까지 적용해 나올 가능성이 높지 않나 생각된다.(....)
이렇게 적고보니 생각보다 무시무시해졌는데, 인텔이 어떻게 할지는 지켜볼 일이다.
그러고 보니 2코어3스레드에 필자가 지은 이름도 Cross Meta Threading으로 CMT이다....
이 두개를 합쳐 그냥 CMT라고 해서 나와도 될듯 =ㅅ=;;
그외 추가될만한건 터보 부스트 정도가 되겠다. 다만 2개 코어가 묶여있으므로
2개 코어 단위로 끄고 켜게 될거고, 당연히 듀얼코어인 경우는 해당되지 않을듯.
여튼 그리해서 나온 다이디자인은 대략 이런 느낌이다.
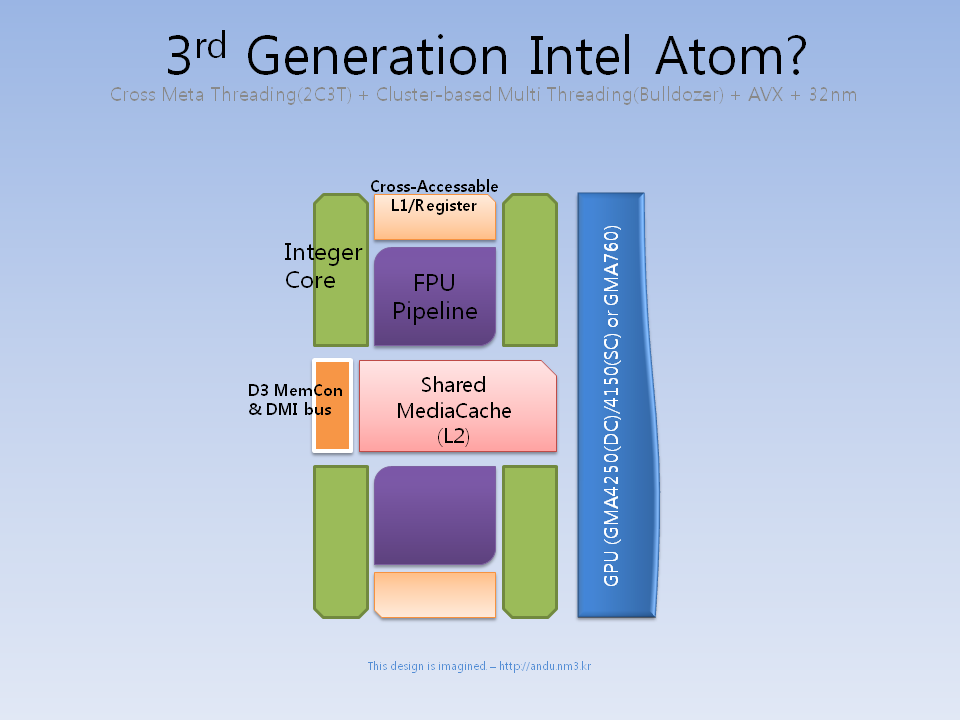
이걸로 인텔은 4코어 6스레드의 3세대 아톰을 손에 쥐는 것이다.
(Cross Meta Tthreading이 적용되어 2코어 4스레드에서 2코어 3스레드로. 즉,
[100% + 50%] + [100% + 50%] => [100%] + [100%] + [100%] 상태가 되어
실질적으로 6스레드는 HT off 기준 6코어와 동등한 셈이다.)
위에서 GPU를 특정하지 않은것은 Z시리즈와 N/D시리즈용으로 나뉘는 IGP는
3세대에서 기존과 거의 비슷하게 유지될 것으로 보이기 때문이다.
물론 GMA500/600의 성능은 좀 어떻게 해줬으면 하는 바램이지만....
32nm면 Z시리즈에 N/D시리즈 급의 GMA를 탑재하는것도 가능하지 않을까 싶다.
여기서 4세대 아톰까지 생각해 보자면, 역시 위에서 언급한
CPU/GPU 가변코어로 넘어갈 가능성이 높지 않나 생각된다.
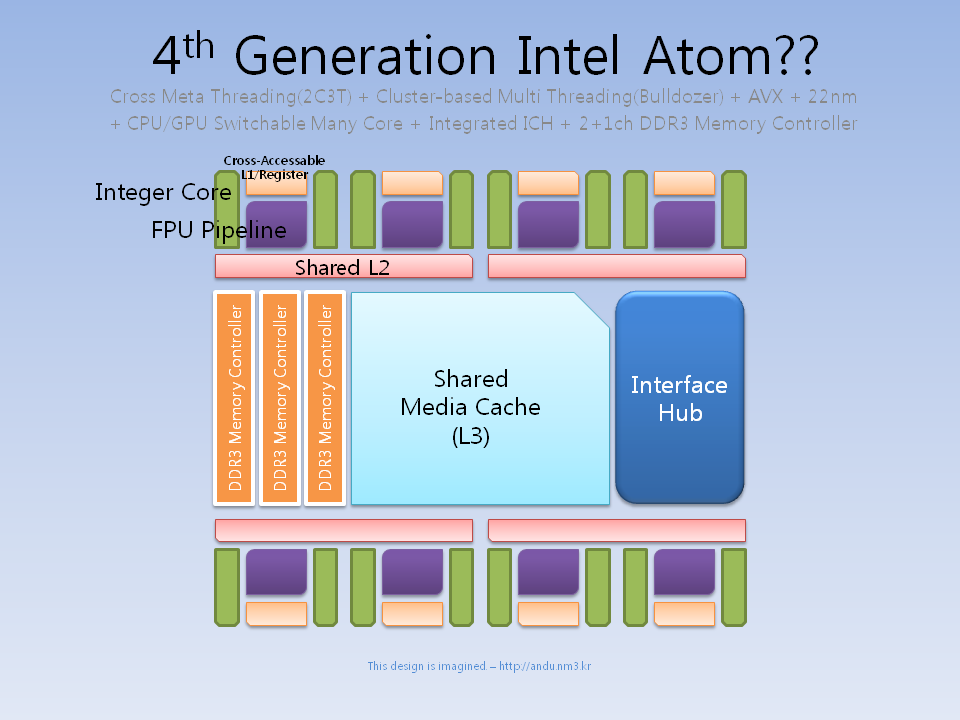
대략 이런 느낌? ...이랄까, 점점 안드로메다로 가고 있다......;;
아무래도 라라비 프로젝트가 그때면 어느정도는 답이 나왔을거라 생각할 수 있고,
라라비가 VGA로써 나오지 못한다고 하더라도, 울트라 모바일 IGP로써
실험용의 총대를 매고 있는 아톰에 적용한다는 것은 꽤 있을법한 이야기이다.
단순 아톰 + 라라비가 아니라, 3세대 아톰 + 라라비 = 4세대 아톰 코어가 되는 셈이니
정말 그럴듯 한 얘기다. 어쨌든 이런 적재적소는 언제나 AMD가 선빵을 본 뒤에 행해졌으니.....
물론 펜4나 펜D처럼 자가 선빵도 있을 순 있지만 말이다....
정리하자면 필자가 예측하는 3세대 아톰은 CMT + CMT + 32nm + AVX...............라고 할 수 있겠다.
근데 Cluster-based Multi Threading은 둘째치고, 단순 본인의 구상에 불과한
Cross Meta Threading을 정말 Intel이 사용할까라는 의구심이 들지만,
2코어 3스레드를 본인만 상상한 것은 아닌듯 싶으니
이미 인텔엔 그런 구상 모델이 있을지도 모르겠다.
결국 예측은 예측이고, 실상은 지켜볼 일이다.